
この記事でわかること
Claude Codeが生成したコードのセキュリティを自動でチェックしてくれる公式プラグインがある。導入は1行、無料、5分で終わる。3層の検出メカニズムと実際に警告が飛んできた体験を書く。
AIが書いたコード、そのままマージして大丈夫?
Claude Codeでコードを書く時間は劇的に減った。ただ、スピードが上がった分だけ「レビューが追いつかない」という別の問題が出てくる。
自分の場合、ブログのAstroテンプレートやPythonスクリプトをClaude Codeに書かせることが多い。動けばOKでpushしかけたことが何度かある。SEの実務でセキュリティレビューをやってきた立場として、これはまずい。
「AIが書いたコードのセキュリティ、どうやって担保するか」——この疑問に対する公式の回答が、2026年5月26日にリリースされた。
security-guidanceプラグインとは
Anthropicが公式に提供する無料のセキュリティ検出プラグイン。
| 項目 | 内容 |
|---|---|
| 提供元 | Anthropic(公式) |
| 料金 | 無料(全プラン対象) |
| 公開日 | 2026年5月26日 |
| ソースコード | GitHubで公開 |
| 要件 | Claude Code CLI v2.1.144以上 + Python 3.8以上 |
やることはシンプル。Claude Codeがコードを書く → プラグインが自動でセキュリティチェック → 問題があれば警告と代替案を提示。人間が「これ大丈夫かな」と目を凝らす前に、機械が先に拾ってくれる仕組み。
3層の検出メカニズム — 玄関・廊下・出口で止める
このプラグインの特徴は、検出が3段構えになっている点。家のセキュリティに例えると分かりやすい。
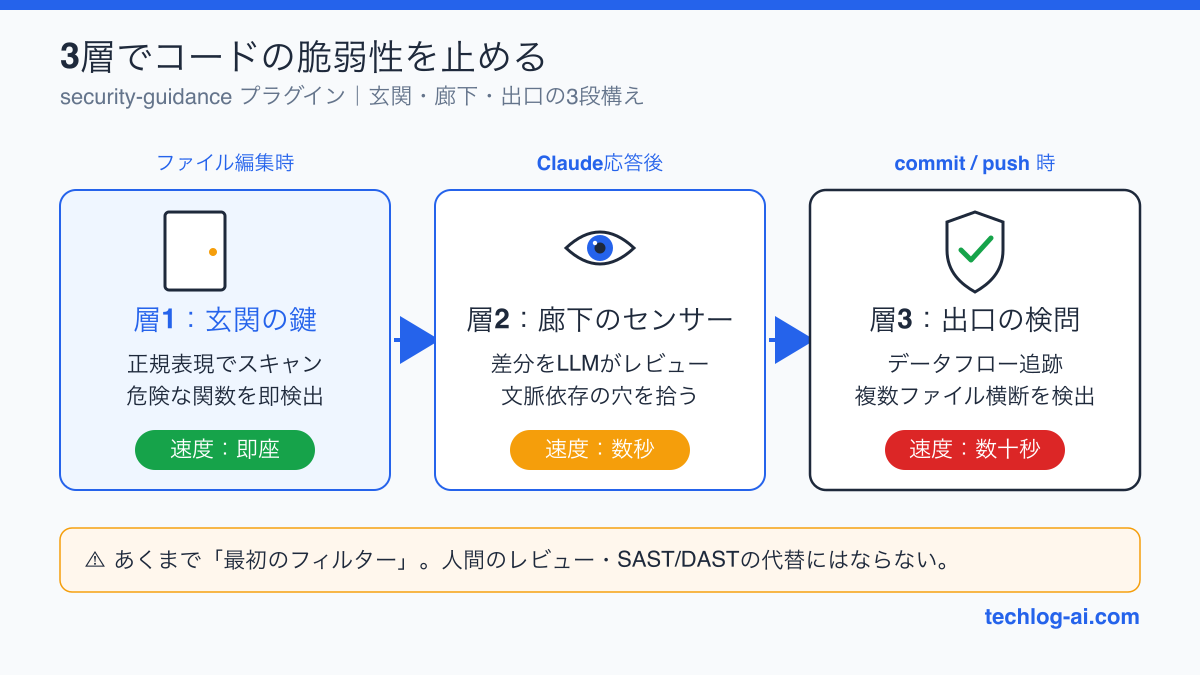
層1:パターン警告(玄関の鍵)
ファイルを編集するたびに正規表現でスキャン。危険な関数呼び出し(動的コード実行、安全でないデシリアライズ、OSコマンド実行、innerHTML代入など)を即座に検出する。
モデル呼び出しなし。だから速い。コードを書いた瞬間に警告が出る。
層2:LLM差分レビュー(廊下のセンサー)
Claudeの応答が終わるたびに、変更差分をバックグラウンドのモデルに送ってレビュー。
層1の正規表現では見つけられない「文脈に依存した脆弱性」を拾う。たとえば、入力値のサニタイズが別ファイルで行われているか、認証チェックが抜けていないか、といった判断。
層3:エージェント型コミットレビュー(出口の検問)
git commit や git push のタイミングで発動。データフロー追跡で、複数ファイルにまたがる脆弱性を検出する。
関連ファイル・呼び出し元・サニタイズ処理まで確認してくれるので、「このファイル単体では問題ないけど、呼び出し元と組み合わせると危険」というパターンも拾える。
| 層 | タイミング | 方法 | 速度 |
|---|---|---|---|
| 層1 | ファイル編集時 | 正規表現 | 即座 |
| 層2 | Claude応答後 | LLM差分レビュー | 数秒 |
| 層3 | commit/push時 | データフロー追跡 | 数十秒 |
導入手順(5分で終わる)
前提条件
- Claude Code CLI v2.1.144以上(
claude --versionで確認) - Python 3.8以上
インストール(1行)
/plugin install security-guidance@claude-plugins-officialこれだけ。設定ファイルの編集も、APIキーの追加も不要。
動作確認
インストール後、適当なPythonファイルで危険な関数を書いてみる。層1のパターン警告が出れば成功。
脆弱なコードを書いたら即警告が飛んできた
ここからは実際に試した話。
テスト用に脆弱性パターンを並べたPythonファイルを用意した。動的コード実行、安全でないデシリアライズ、OSコマンド実行、SQLインジェクションなど教科書的なパターン6つ。ここに新しい脆弱性パターンを3つ追加してみた。
ファイルを保存した瞬間、こうなった:
⚠️ Security Warning: Using [dangerous function] can lead to
command injection vulnerabilities.
This codebase provides a safer alternative: [safe module path]
Instead of:
dangerous_func(`command ${userInput}`)
Use:
import { saferAlternative } from '[safe module]'
await saferAlternative('command', [userInput])層1のパターン警告がすぐに反応。危険なパターンを検出して、安全な代替手段まで提示してきた。
ポイントは3つ:
- 書いた瞬間に出る(保存を待たない)
- 何が危険かを説明してくれる(「コマンドインジェクションにつながる」)
- 代替手段を具体的に示す(「このユーティリティを使え」)
「危ないよ」で終わらず「こう直せ」まで出してくれるのが実用的。レビュー依頼を出す前に自分で気づけるのは大きい。
さらに面白かったのは、この記事の原稿を書いている最中にも警告が出たこと。Markdownファイルの中にコード例として脆弱なパターンを書いただけで、プラグインが反応した。コードブロック内のサンプルまで検出するのは予想外だったし、それだけ「漏れなく拾う」という設計思想が徹底されている。
チームのセキュリティルールを追加する方法
デフォルトのパターンだけでは足りない場合、2つのファイルでカスタマイズできる。
自然言語ルール
.claude/claude-security-guidance.md に自社ルールを書く。
- 本番DBへの直接接続はreplicaを使うこと
- S3バケット名をハードコードしない
- JWTの有効期限は1時間以内にする自然言語で書けるので、非エンジニアのPMでもルール追加が可能。
正規表現パターン
.claude/security-patterns.yaml に独自パターンを追加できる。たとえばAWSアクセスキーのハードコード検出パターンなど、自社固有のルールを正規表現で定義する。
読み込み順はユーザー全体 → プロジェクト → ローカル。プロンプト予算は合計8KB。
主な環境変数
| 変数 | 値 | 効果 |
|---|---|---|
| SECURITY_REVIEW_MODEL | claude-opus-4-7(デフォルト) | レビューに使うモデルを変更 |
| SECURITY_GUIDANCE_DISABLE | 1 | プラグイン全体を無効化 |
| ENABLE_PATTERN_RULES | 0 | 層1(パターン警告)を無効化 |
| ENABLE_COMMIT_REVIEW | 0 | 層3(コミットレビュー)を無効化 |
これだけで安心してはいけない3つの理由
ここは大事なので強調しておく。
1. ベストエフォート型のツール
完全な保証はない。脆弱性を見逃す可能性も、誤検出もある。Anthropic自身が「補助ツール」と明言している。
2. 人間のレビューは省略できない
SAST/DAST、ペネトレーションテスト、人間によるコードレビュー。これらの代替にはならない。あくまで「最初のフィルター」。
3. コード差分がAPIに送信される
変更差分やファイル内容がAnthropic API(またはBedrock/Vertex)に送信される。機密性の高いコードを扱うプロジェクトでは、チームのセキュリティポリシーと照合する必要あり。
ログは ~/.claude/security/log.txt にローカル保存(ファイル内容は含まない)。外部へのログアップロードはなし。
5分の投資でコードレビューの安心感が変わる
Anthropicの内部テストでは、PR上のセキュリティ指摘が30〜40%減ったという数字が出ている。
「万能ではないが、ないよりはるかにマシ」——SE視点だとこの表現が一番しっくりくる。コードレビューで脆弱性を指摘する工数が減るだけでも、チームの生産性は上がる。
導入は1行、無料、5分。Claude Codeを使っているなら、入れない理由がない。
セキュリティをもっと深く学びたいなら
AI生成コードの安全性を理解するには、そもそものセキュリティの基礎知識が必要。Udemyにはセキュリティ・クラウドセキュリティの講座が豊富にある。セール時なら1,500円前後で受講できるので、気になる分野から1本試してみるのがいい。
関連記事
- Claude Code開発者の11のTips、週末SEが実際に試してみた — Claude Codeの使い方をさらに掘り下げたい人向け
- Claude Proプランで使用量制限を突破した5つの工夫 — Claude Code運用のコスト管理
