
スクリーニング通過 ≠ 買っていい
前回の記事で書いた通り、screen.pyは東証プライム1,574銘柄を30分で走査して、配当利回り・自己資本比率・配当性向・営業利益率の4条件で候補を絞り込む。
問題はその後だ。
スクリーニングを通過した銘柄を手元に並べたとき、「この11銘柄、どれが本当にいいの?」という疑問が出てくる。利回りが高いからスクリーニングを通過した。ただそれだけで、過去5年のEPSが伸びているか、配当が一度でも削られたか、営業CF(キャッシュフロー)が安定しているか——そういった「時系列での確認」は何もできていない。
そこで作ったのが deepdive.py。スクリーニング通過銘柄だけを対象に、5年分の財務データで8軸評価・スコアリングする仕組みだ。
設計思想:「利回りより、EPSの継続性」
高配当株投資で最終的に怖いのは、減配だ。配当が削られれば利回りも下がり、株価も下がる。ダブルパンチ。
減配リスクを最小化するには何を見るべきか。SE的に整理すると、**「企業が稼ぎ続けているか」**に尽きる。
1株利益(EPS)が連続して増えているなら、会社は稼ぐ力を維持・拡大している。配当の原資が増えているなら、減配リスクは下がる。
この考え方で、EPS連続性を他の指標より重く評価する設計にした。
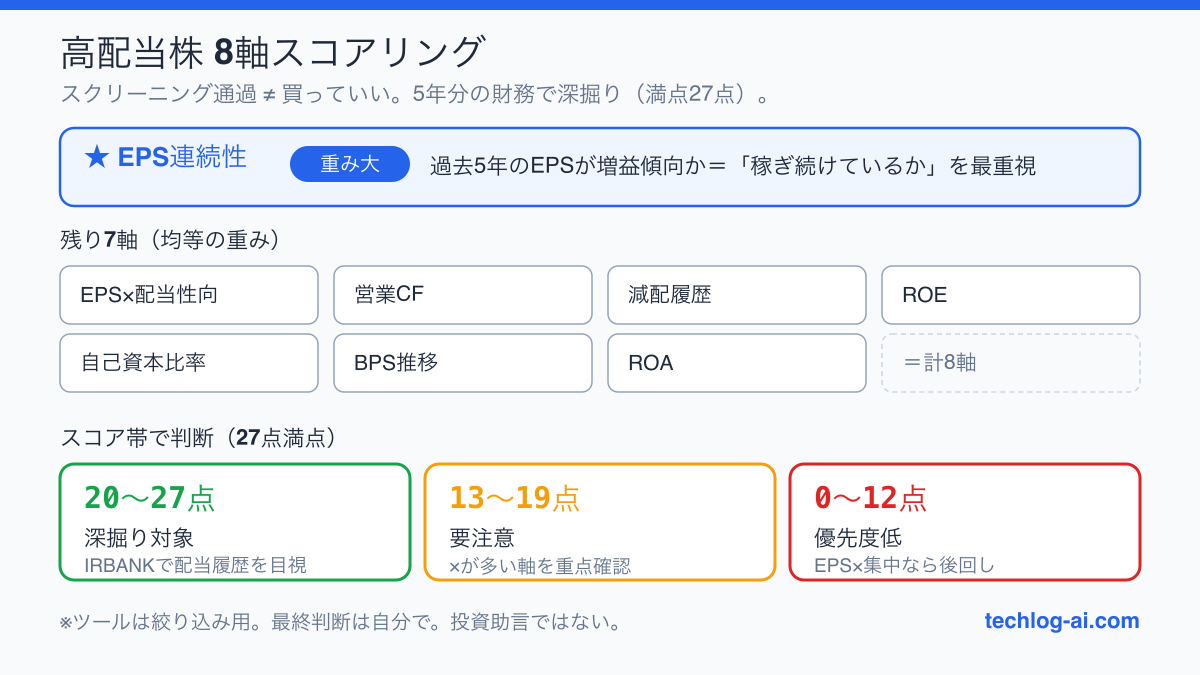
8軸スコアリングの全体像
deepdive.pyは以下の8軸で評価する。満点は27点。
| 評価軸 | 何を見るか |
|---|---|
| EPS連続性 | 過去5年のEPSが増益傾向か(赤字・減益の頻度) |
| EPS×配当性向 | 増益傾向かつ配当性向が持続可能な水準か |
| 営業CF | 営業キャッシュフローが安定して黒字か |
| 減配履歴 | 過去に配当を削ったことがあるか |
| ROE | 自己資本を使って効率よく稼いでいるか |
| 自己資本比率 | 財務の安定性(借金の少なさ) |
| BPS推移 | 1株当たり純資産が積み上がっているか |
| ROA | 総資産を使った収益効率 |
重みはEPS連続性だけ他と異なる設定にしている(具体的な重み比率は非公開)。
なぜEPS連続性だけ重みが違うのか
理由は2つ。
1つ目は、日本の著名な個人投資家が実践するスクリーニング順序をそのまま実装したこと。配当投資の文献を複数参照した結果、「EPS安定確認を最初のフィルタにする」という判断は複数の実践家が共通して挙げていた。
2つ目は、実際にスクリーニング通過銘柄を並べたとき、EPS連続増益の銘柄と断続的に赤字を出す銘柄では、直感的な信頼度がまったく違った。「自分がここで買いたいか」という感覚がEPSに連動していた。
定量的な論文根拠ではなく、実践者の知恵と自分の感覚を設計に落とし込んだ判断だ。
スコアの見方
| スコア帯 | 判断の目安 |
|---|---|
| 20〜27点 | 深掘り対象。IRBANKで過去10年の配当履歴を目視確認 |
| 13〜19点 | 要注意。×が多い軸を重点確認。1〜2軸なら許容範囲のこともある |
| 0〜12点 | 確認コスト高・優先度低。EPS連続性に×が集中するなら深掘りの優先度を下げる |
1点ポイントとして、EPS連続性だけ×でも他が全◎なら個別判断の余地がある。業種の特性(インフラ・公益系など)や一時的な特別損失による影響の場合があるため。
yfinanceとみんかぶで数値がズレる理由
スクリーニング段階で配当性向の上限を60%に緩めているのは、yfinanceの計算方式が原因だ。
yfinanceはTTM(過去12か月の実績値)ベースでEPSを計算する。一方、みんかぶや会社四季報が表示するのは会社側の「予想EPS」ベースの数値。
具体的に起きること:直近12か月に一時的な費用計上があって純利益が下がると、yfinanceのEPSが一時的に低くなる。その結果、配当性向(= 配当 ÷ EPS)が高く計算される。
たとえば配当性向を「40%まで」で線引きすると、本来は健全な銘柄が「55%超」として弾かれる可能性がある。
対策として、screen.pyのスクリーニング段階では配当性向の上限を60%に緩めて「取りこぼし防止」にする。その後のdeepdive.pyで5年分の実績データを見て精査する——という2段階の設計にしている。
実際に動かした結果(銘柄名は非公開)
スクリーニング通過銘柄を deepdive.py にかけると、HTMLレポートとして出力される。銘柄ごとにEPS推移・配当推移・営業CF推移・ROE推移・自己資本比率推移の5チャートが並ぶ。
実際の数字を見ると、決算発表の前後でスクリーニング結果が大きく変わることが分かった。
| 実行日 | 通過銘柄数 | 状況 |
|---|---|---|
| 5月9日 | 11銘柄 | 3月期決算発表前 |
| 5月17日 | 115銘柄 | 3月期決算発表後 |
1週間で11銘柄から115銘柄へ。10倍超の急増だ。
これは5月が3月期決算企業の本決算発表ラッシュのタイミングだからだ。多くの企業が2025年度の業績と配当金額を確定発表したことで、yfinanceのデータが一斉に更新された。スクリーニング条件を満たす銘柄の数がまるごと入れ替わった。
逆に言えば、1回だけ実行して終わりにしていたら、この115銘柄は一切見えていなかった。週次実行の価値が数字で証明された瞬間だった。
銘柄名は記事では公開しない。この記事は「ツールの設計と使い方」の紹介であり、特定銘柄の推奨ではないからだ。
傾向として、スコア上位に入る銘柄はEPSが5年近くにわたって右肩上がりで、配当を一度も削っていない。直感的に「これなら長期で持てる」と感じる銘柄が上位に来る設計になっていた。
ツールを使った所感
毎週土曜の午前中、35分でスクリーニング → 2分で深掘りレポート生成、という流れが定着した。
5月の決算発表ラッシュで115銘柄が通過したとき、deepdive.pyの必要性をあらためて実感した。115銘柄をIRBANKで1社ずつ手動確認するのは現実的でない。deepdive.pyにかければスコア順に並び、20点以上の銘柄だけを目視確認すればいい。絞り込みの量と質が両立できる。
以前は「気になる銘柄をIRBANKで1社ずつ見る」という作業を繰り返していた。それが今は「スコア20点以上の候補だけをIRBANKで確認する」に変わった。見る銘柄の数が大幅に減り、確認の質が上がった。
ただし、ツールはあくまで「確認対象の絞り込み」に使うもの。最終的な投資判断は自分でIRBANKやカブタンの情報を見て行う。deepdive.pyのスコアが高い銘柄が「必ず良い」わけではないし、この記事は投資助言ではない。
まとめ:設計で解決した3つの問題
- 「スクリーニング後に何を見るか分からない問題」 → 8軸スコアリングで優先順位を自動付け
- 「yfinanceの数値がみんかぶとズレる問題」 → スクリーニング段階で条件を意図的に緩め、深掘りで精査する2段階設計で吸収
- 「決算シーズンに候補が一気に増えて手が回らない問題」 → deepdive.pyのスコアで115銘柄でも2分で優先順位づけ
どちらも「手動でやるには限界がある」問題を、Claudeと対話しながら設計・実装した。コードより先に設計を固めたことで、実装はほぼ迷わずに進められた。この「Claudeに自分専用のツールを設計させる」感覚は、副業作業にだけ効くスキルを抜き出した話とも地続きだった。コードを書く人でなくても、繰り返し作業を仕組みにする発想は変わらない。
ただし、課題も出てきた。5月の決算シーズンで115銘柄が通過したように、時期によってはスクリーニング条件が緩すぎる可能性がある。11銘柄なら全件deepdive.pyにかけられるが、100銘柄超になると処理時間も増え、その後の確認作業も重くなる。
スクリーニング条件をもう少し厳しく絞る設定(配当利回りの下限を4%に引き上げるなど)も今後の検討対象だ。毎週の実行結果を見ながら、条件のチューニングを続けていく。
Pythonでこういったツールを自作したい場合、Udemyの「データ分析」「pandas」あたりで検索すると体系的に学べる講座が見つかる。
※本記事はPythonを使ったツール設計の紹介を目的としています。特定の銘柄の売買を推奨するものではなく、投資判断はご自身の責任でお願いします。
